Authenticating Web Scrapers in Python
March 31, 2013 — Alex Guerra
So, you're trying to use python to scrape some website, but you want to grab pages that you have to be logged in to access and you don't know what to do.
Good news.
Because that's what I'm writing about. And it's super easy. So aren't you so excited? Aren't you so ready to get started?
Well slow down: First I have to give you a brief rundown of what's going to be happening from a more theoretical standpoint. That all starts with talking about how websites "know" that you're logged in.
Background
When you type in your username and password and press that login button, a request containing your login info is created and sent from your browser to the server. If the server checks your credentials and accepts them, it sends you back a cookie. Your browser takes this cookie and saves it. All subsequent requests made by your browser to the website in question contain that cookie. The server recognizes the cookie you sent as the cookie it gave you, and your request is successfully authenticated. Pretty simple, eh?
Usually when doing really basic scraping every request is sent without regard for cookies. That ain't gonna cut it here; because we don't persist cookies, we can't send our cookie, which means we can't make requests that are authenticated. No good.
What we need to do is find a way to construct a "login" request with some credentials, get whatever cookie the server responds with, and then send that cookie back with every request we make after. Luckily the Session object from the excellent requests library handles the entirety of the second part: every cookie that the server sets is saved in the session and sent back with every other request made by the session. The only thing we really need to do then is figure out how to construct and send a "login" request.
So let's get started. Step one:
Make sure you're not trying this on http basic auth
This is pretty simple, but an important distinction. If you see something like the image below then your adventure stops here; this is the page you've been looking for.

Otherwise, it's on to step two:
Inspect that request
Now we have to check out a login request so we can find out exactly whats inside. Here I'm going to be using chrome developer tools, but basically anything that can inspect http requests will work. Head to the login page for the site you want to scrape and open up the chrome dev tools panel (right-click anywhere > inspect element). Then head over to the network tab. Here chrome keeps information on all requests and responses sent to and from your browser tab. Press clear to empty the tab and then click record.
Next we're going to send out the login request to catch and inspect. Enter your information into the page's login form and press submit. You should see a bunch of movement in your network tab. Scroll to the top of it and look for a POST request named something like 'login'. It should be the first request, but sometimes ajax requests tarnish the clean network tab before you try to login.
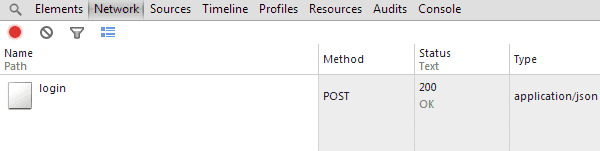
Click the request and make sure you're on the headers tab. Here is the data from the POST request you sent. Copy down the 'Request URL' and then scroll down to the section titled 'Form Data' and copy all of it down as well. The form data should be pretty straightforward; a set of key-value pairs containing your username/email and password in plaintext with maybe a couple of other random fields.
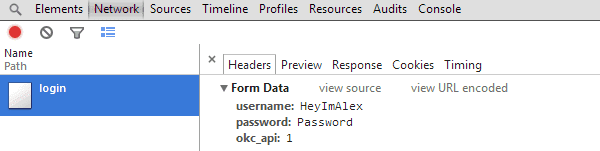
Note: If inside the form data there's a field with a strange long random string or if your username or password aren't in plaintext, read the addendum section at the end; you're probably going to need to do a little more work.
Constructing your request
So, now we know where the login request is sent (that 'Request URL' we copied down) and what is sent in it (from the 'Form Data'). Time to open up your favorite text editor and finish this thing off.
import requests
login_data = {
'username': 'HeyImAlex',
'password': 'Password',
}
s = requests.Session()
s.post('http://www.okcupid.com/login', data=login_data)Easy, yeah? Let's go through that line by line. First I made a dict, login_data, that contains the field data we copied earlier (you can usually ignore the more obscure fields). Then I created a requests Session object and from it sent a POST request containing my login data to the 'Request URL' I copied down earlier. Our session object, s, will save the cookie that the server responds with and all further requests made from s will be authenticated. Hooray!
Celebrate
Well, hope you enjoyed this quick introduction to the wonderful world of web scraping. On top of learning how to authenticate requests, you also got a pretty decent primer on interacting with websites programatically; the same techniques (that is, executing an action, examining the request sent, and reimplementing it in code) can be used to reverse engineer all of the aspects of a website into code. Happy scraping!
Debugging: Addendum
There are plenty of issues you can run into when trying this, but the gist of my advice is this: think like a developer. At the end of the day the browser isn't magic; you have everything you need to construct the request, you just have to figure out how to put it all together. Examine the successful request you intercept and figure out where that input comes from. Is it in html of the login page in the way of a csrf token? Is it set by js? Is it always the same or different every time? Whatever you do, don't give up. I've seen some pretty obnoxious login systems before, but nothing I couldn't break. If you're really desperate you can shoot me an email at alex@heyimalex.com.
I believe in you.